PDF 是我们打交道最多的文件格式之一。提到这个格式,即使是对技术并不熟悉的用户,也能说出「通用性好」、「格式不会乱变」这些优点。但同时,PDF 也是让我们感到困惑最多的格式之一,因为与 Word 文档等其他常见办公软件格式相比,PDF 似乎有着太多的「怪癖」,例如复制文字困难、几乎没法编辑等等。PDF 软件数量繁多、质量良莠不齐的现状,也进一步让很多用户无法正确理解和使用 PDF。
然而,事实并非如此。这些问题大多不是 PDF 格式的「缺陷」,而是因为我们在观念上把 PDF 当成了和其他办公文档格式相近的东西,并因此期待 PDF 也具有和后者相似的功能和特征。
尽管 PDF 格式和 Word 格式在实际用途上有诸多重叠之处,但那只是表面现象。从技术角度看,两种格式之间的差异要远远大于 Word 文档和网页之间的差异,甚至还要大于 Word 文档和 Excel 表格之间的差异。
但这并不意味着 PDF 就是一种难以理解的格式。恰恰相反,对大多数用户来说,PDF 可能是他们接触到的格式中最「接地气」、与现实生活最接近的。因为,PDF 与其说是一种数字文档,不如说是实体文档在数字世界中的影像。对 PDF 的操作,很大程度上可以看成对真实纸张的操作,只是操作环境从物理世界换到了数字世界而已。PDF 的创建就是一种虚拟的打印,复制 PDF 文字的过程更像是一种抄写,而 PDF 的编辑实质上是一种涂改。
一旦接受了这个观念,PDF 的很多「怪癖」就显得顺理成章了:打印出来的东西当然不会因为位置的变化而改变外观;抄写的结果很可能与原文存在误差,并且受制于抄写者对文字的理解;涂改的可行性则取决于原有布局留下了多少改动空间,并且再轻微的涂改也会对纸张造成损伤。
当然,只给出这样的结论并不足以令人信服。因此,下文的主要任务就是通过回答几个关于 PDF 格式普遍关心的问题,结合 PDF 的结构和语法,解释为什么「PDF 的本质就是数字化的纸张」,从而深化对 PDF 格式的理解。
为什么 PDF 的外观非常稳定?
在我们日常使用的文档格式中,PDF 文件的外观是最稳定的。一经生成,无论在什么操作系统上、用什么软件打开,得到的显示效果几乎总是一致的。相比之下,Word 所使用 docx 格式的保真性就差得多了:哪怕只是换台电脑,显示效果都可能发生了变化,更不要说用不同版本的 Word 或者第三方软件打开了。
PDF 的这种保真性让它广受青睐,但它究竟是如何做到这一点的?PDF 的稳定是绝对的吗?
「打印」出来的 PDF
如果平时注意观察,容易发现各种软件中涉及 PDF 的操作,用词都比较特别。其他格式都是被「新建」(new / create)出来或者「保存」(save)下来的,只有 PDF 是被「导出」(export)甚至「打印」(print)出来的。这些词语并不是随意选用的,它们本身就说明了 PDF 的重要特征:「导出」暗示着文件编辑已经告一段落,而「打印」则更是形象地表明 PDF 的创建是一个「固化」的过程。
为了进一步理解这种区别,让我们来对比一组外观上完全相同的 Word 文档和 PDF 文档。下图中,右侧的 PDF 格式文件是由左侧的 Word 文件导出得到的,两者的内容都只有「Hello world!」一行居中文字。(注:为了避免不必要的复杂性,我们暂时只以英文文档为例。)
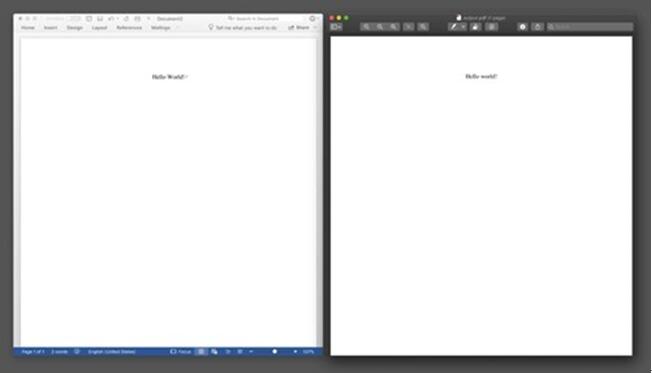
PDF数字界的纸张:科普向图一
先来看 Word 是如何实现这一版式效果的。用任意解压工具将该文档解开(docx 文件 实质上 就是一个压缩包),找到其中的 /word/_rels/document.xml 并打开。其中的关键部分如下(代码经过整理):

PDF数字界的纸张:科普向图二
不必恐惧这些陌生的代码,它们的意义很容易从文档内容本身反推出来。先看倒数第二行,这里记录了整个文档最重要的信息——「Hello world!」这串文字。在它的上面一行,w:rFonts 属性将字体设置为 Times。那么前四行是做什么的呢?从第二行的 center 字样不难猜出,它们控制的是文字所在段落的样式,包括居中对齐等等。
这就是 docx 格式这类 标记语言 (Markup Language)文档的特征:在纯文本上包裹各种「标签」(tag)来描述文本的样式(颜色、位置、字体等等),从而获得格式丰富多变的文档。常见的网页(HTML)、Evernote 笔记( ENML )所用的语法本质上都是标记语言,区别只在于支持的标签各不相同、因此能实现的格式有多有少罢了。
PDF 又是怎么做的呢?我们用纯文本编辑器打开上图中的 PDF 文件(是的,PDF 可以用文本编辑器打开查看源码),其中的关键部分如下(经过处理):
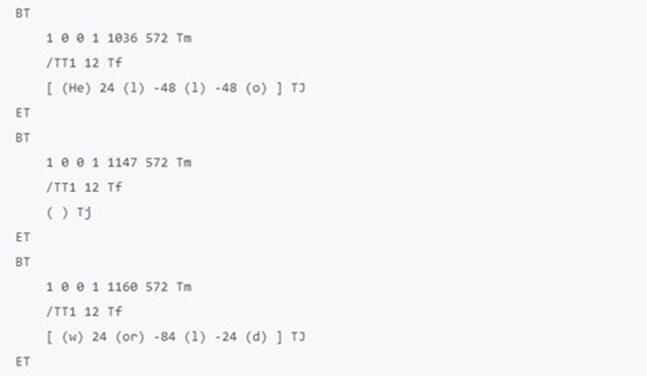
PDF数字界的纸张:科普向图三
即使你被这些凌乱的数字和代号弄得一头雾水,大概也能看出它与 docx 格式有着截然不同的画风。如果我们粗略地把这些语句翻译成「人话」:

PDF数字界的纸张:科普向图四
请在头脑中想象一下这个过程——是不是有一种强烈的「机械感」?如果说 Word 文档使用的标记语言很像是给人下命令(「这里有一段话,把它用 Times 字体写出来,位置上居中对齐……」),那么 PDF 的语言则更像是在控制机器,定位、调整、落笔、抬起,移动到下一行;如此重复。联想一下,铅字排版和打印机的工作机制不也是类似的吗?可见,用「打印」一词来搭配 PDF 是十分恰当的。
如此对比之下,PDF 显示效果的保真性就容易解释了。虽然 Word 格式使用的语法明显更容易理解,但问题在于不同「人」——不同软件环境——听到同样一段指令,头脑中的反应未必是相同的。「用 Times 字体显示」——哪个是 Times 字体?没有安装这个字体怎么办?「居中对齐」——以什么为参照物居中?怎么计算居中?Word 文档对此笑而不语,把问题留给了软件去思考。正是这种自由裁量的空间为显示效果的差异留下了隐患。
PDF数字界的纸张:科普向图五
在 PDF 中,这样的问题就很难出现。与标记语言那种相对的、描述式的标签不同,PDF 语言几乎都是绝对的、指令式的。例如,上面的 PDF 中,文字明显是居中的,但代码中从头到尾没有半个字提到「居中」;相反,它直接指明了文字的坐标。因此,无论什么阅读器读到这份文件,只要根据坐标「照葫芦画瓢」地绘制,一定能得到相同的显示效果。
类似地,下面这段代码的作用是绘制出一个点状的「L」形,很难想象它会给软件留下什么「自由发挥」的空间:

PDF数字界的纸张:科普向图六
PDF 外观稳定性的另一个原因是它嵌入了各种需要用到的外部资源。我们注意到,上面的 PDF 在设置字体时,没有像 docx 文件那样直接指定字体名称,而是引用了一个代号般的 /TT1。实际上,/TT1 指向的是一个内嵌的字体,存储在 PDF 内部的偏后位置。显示时,阅读器将根据这个代号找到字体,按照其中记载的形状、宽度等信息,将字符「书写」在指定的坐标上——就好比活字排版工按指示从字盘中取出字模,并放在母版上的特定位置一样。相反,Word 文档默认是不嵌入字体的;只要另一台电脑上没有安装用到的字体,或者安装了不同版本的字体,就会导致显示效果的差异。